找個方法測試 PDEP 指令在哪個 CPU 上可以高效執行。
封面 (Gemini 生成)
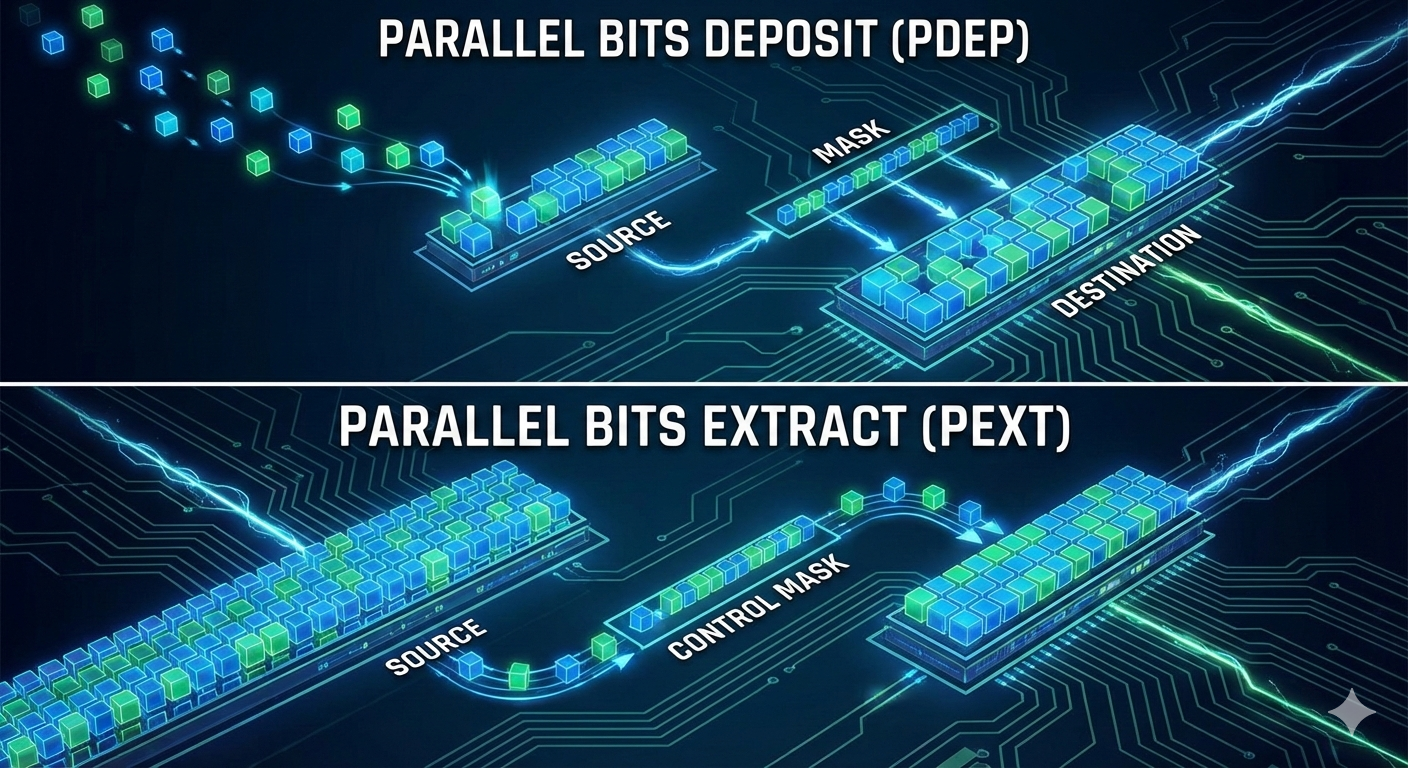
實驗室同學使用 PDEP(Parallel Bits Deposit),結果在不同世代的 CPU 上效能差異非常明顯。簡單說明一下:PDEP 會把來源操作數(source)中的位元,根據掩碼(mask)指定的位置,按位「寫入」到目標位址;這在某些位元重排、壓縮或稀疏資料操作上很方便,但代價會隨 CPU microarchitecture 而變。除了 PDEP,還有相對應的 PEXT(Parallel Bits Extract),功能相反,是從來源根據掩碼「讀取」位元。
那位實驗室同學說 AMD Zen2 把 PDEP 用 microcode 實作,單次成本高達數十個 cycles(約 18 cycles),而 Zen3, Zen4 則已優化到幾乎 1 cycle 級別。但是我找不到哪邊有紀錄特定 CPU 是否有硬體支援,為了量化差異,我用 GPT-5.2 寫了下面的簡單 benchmark 並用 perf 測量 cycles / instructions:
#include <immintrin.h>
#include <stdint.h>
volatile uint64_t x = 0x12345678abcdef00;
volatile uint64_t m = 0x0f0f0f0f0f0f0f0f;
int main() {
for (long i = 0; i < 100000000; i++) {
x = _pdep_u64(x, m);
}
return 0;
}
建置與執行指令(需要 root 權限調整 perf 設定):
gcc -O2 -march=native -fno-unroll-loops pdep_test.c -o pdep_test
sudo sh -c 'echo -1 > /proc/sys/kernel/perf_event_paranoid'
perf stat -e cycles,instructions ./pdep_test
測試結果(摘要):
- Zen2: 約 3.22 秒,cycles 非常多,insn-per-cycle 約 0.04(表示每 cycle 做不到一條真正有用的指令,PDEP 成本很高)。
- Zen3, Zen4: 約 0.08 秒,insn-per-cycle 約 1.99(表示新的 microarchitecture 對此指令支援非常好)。
因此實務上有兩個重點:
- 如果程式在熱路徑使用 PDEP,先檢查目標機器的 microarchitecture(Zen2 上代價很高)。
- 若需兼容舊架構,考慮替代實作(例如查表、分步位元操作或其他演算法),不要盲目使用 PDEP。
以下附上原始執行結果(perf 輸出),以保留量測數據的原貌:
Zen2 (AMD 3995WX):
Performance counter stats for './pdep_test':
138,0401,0677 cycles
6,0497,7257 instructions # 0.04 insn per cycle
3.219002626 seconds time elapsed
3.218976000 seconds user
0.000000000 seconds sys
Zen3 (AMD 5950X):
Performance counter stats for './pdep_test':
3,0150,2663 cycles
6,0115,6546 instructions # 1.99 insn per cycle
0.064414565 seconds time elapsed
0.064444000 seconds user
0.000000000 seconds sys
Zen4 (AMD 7960X):
Performance counter stats for './pdep_test':
301,696,917 cycles
601,260,525 instructions # 1.99 insn per cycle
0.080170710 seconds time elapsed
0.080307000 seconds user
0.000000000 seconds sys
參考資料:
- https://www.felixcloutier.com/x86/pdep
- What are assembly instructions like PEXT actually used for?
- Top 10 Craziest Assembly Language Instructions
- Yedidya Hilewitz, and Ruby B. Lee. “Performing Advanced Bit Manipulations Efficiently in General-Purpose Processors,” In: 18th IEEE Symposium on Computer Arithmetic (ARITH-18 2007), 25-27 June 2007, Montpellier, France, pp. 251-260. 2007. DOI: 10.1109/ARITH.2007.27. https://www.lirmm.fr/arith18/papers/hilewitz-PerformingBitManipulations.pdf
本文部分內容由GPT-5 mini協助生成,作者具備相關專業能力,對 AI 產出內容進行審核與把關,並對文章的正確性負最終責任。若文中有錯誤之處,敬請不吝指正,作者將虛心接受指教並儘速修正。