產生無換行的參考文獻,不用手動刪除換行。
用於上傳論文比對系統
前言
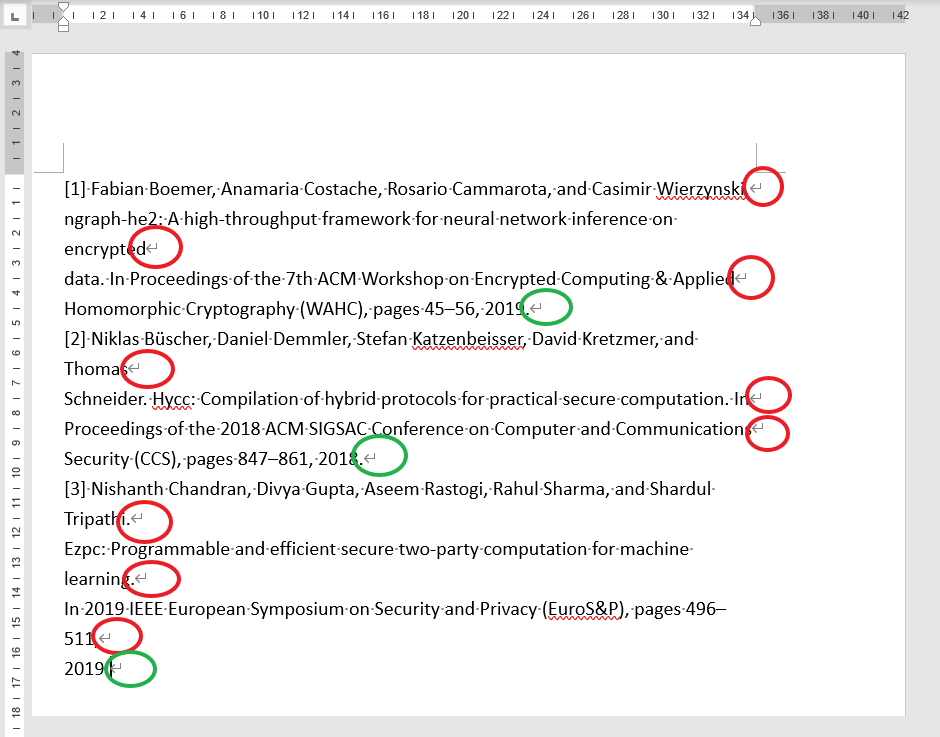
直接從 pdf 複製參考文獻到 word 會產生如下圖情況,紅框是我們不要的換行,綠框是要的。
Unwanted line breaks
發現有個檔案 (.bbl) 會隨著 latex 編譯成 pdf 時產生,裡面是參考文獻的文字檔不過有一些 latex 語法。經過實測,latex 語法並不會事先被處理,例如 Tram{\`{e}}r 不會先轉成 Tramèr 再放到 .bbl。這個問題有些棘手,我可不想寫一個編譯器來解決。
觀察編譯後產物,有個 .bbl

Step 1
所以第一步我們先使用 pandoc 這個線上轉換工具,直接把 .bbl 內容貼過去再按 Convert。工具連結:
右下角是轉換後的文字

Step 2
轉換後會用一個空行隔開每個項目,寫個簡單的 python script 來把每個項目的內容合併即可。
# Step 1: copy .bbl to online converter and copy result to in.txt
# https://pandoc.org/try/?params=%7B%22text%22%3A%22%22%2C%22to%22%3A%22plain%22%2C%22from%22%3A%22latex%22%2C%22standalone%22%3Afalse%2C%22embed-resources%22%3Afalse%2C%22table-of-contents%22%3Afalse%2C%22number-sections%22%3Afalse%2C%22citeproc%22%3Afalse%2C%22html-math-method%22%3A%22plain%22%2C%22wrap%22%3A%22auto%22%2C%22highlight-style%22%3Anull%2C%22files%22%3A%7B%7D%2C%22template%22%3Anull%7D
# Step 2: python3 utils/bib_plain.py in.txt >| out.txt
import sys
in_file = sys.argv[1]
lines = ""
with open(in_file) as fp:
lines = fp.readlines()
bibitems = " ".join(lines).split("\n \n")
for idx, bibitem in enumerate(bibitems):
bibitem = bibitem.replace("\n", "").strip()
print(f"[{idx+1}] {bibitem}")
Remove all unwanted line breaks

後記
不用 pandoc 而是直接從 pdf 複製文字也可以,不過要改一下 step 2 python script 的邏輯,改成去看 [ 當作項目分隔處。