畫大量資料發現效能太差,光讀取 CSV 就可以差一百倍,輸出的 pdf 檔案大小也有五倍差距。
TL;DR
Environment
- WSL2 Ubuntu 18.04
資料產生範例
Fixed point 與 floating point 的乘法絕對誤差1
#include <cstdint>
#include <fstream>
#include <iostream>
#include <random>
static constexpr int N = 5'000'000;
static constexpr float RANGE = 10.0;
static constexpr int FRACTION_BITS = 10;
static constexpr int SCALING_FACTOR = 1 << FRACTION_BITS;
std::mt19937 gen(0);
std::uniform_real_distribution<float> dis(-RANGE, RANGE);
#define FLOAT_TO_FIXED(x) \
(static_cast<uint32_t>( \
static_cast<int32_t>(x * \
static_cast<float>(SCALING_FACTOR))))
#define FIXED_TO_FLOAT(x) \
(static_cast<float>(static_cast<int32_t>(x)) / \
static_cast<float>(SCALING_FACTOR))
uint32_t fixed_point_mul(uint32_t x, uint32_t y) {
return static_cast<uint32_t>(
(static_cast<int32_t>(x) * static_cast<int32_t>(y))
>> FRACTION_BITS);
}
int main(int argc, char *argv[]) {
std::ofstream out("data.csv");
for (int i{0}; i < N; ++i) {
auto x = dis(gen);
auto y = dis(gen);
auto z_float = x * y;
auto z_fixed =
FIXED_TO_FLOAT(
fixed_point_mul(FLOAT_TO_FIXED(x),
FLOAT_TO_FIXED(y)));
if (i > 0) {
out << ',';
}
out << std::abs(z_float - z_fixed);
}
out.close();
return 0;
}
$ g++ -std=c++1z -o data_gen data_gen.cpp
$ time ./data_gen
real 0m1.862s
user 0m1.829s
sys 0m0.030s
$ ls -lh data.csv
Permissions Size User Date Modified Name
.rw-r--r-- 54M ben 4 Mar 16:58 data.csv
Python Environment
$ virtualenv -p python3.7 venv3.7
$ source venv3.7/bin/activate
$ pip install matplotlib numpy pandas
Read CSV
首先第一個遇到的困難就是讀取 CSV 太慢,按照網路上找的各種方法2,其實在小量資料下可以採用,不過我測試了一些方法,最後發現第三種版本可以最快的讀取 CSV 到 numpy array 中。
- v1_read_csv.py
import numpy as np
fin = "data.csv"
data = np.genfromtxt(fin, delimiter=',')
print(data)
$ time python3 v1_read_csv.py
[0.00228202 0.00304794 0.00644779 ... 0.00259626 0.00812531 0.00063801]
real 0m38.557s
user 0m35.961s
sys 0m2.834s
- v2_read_csv.py
import pandas as pd
fin = "data.csv"
df = pd.read_csv(fin, sep=',',header=None)
data = df.to_numpy()[0]
print(data)
$ time python3 v2_read_csv.py
[0.00228202 0.00304794 0.00644779 ... 0.00259626 0.00812531 0.00063801]
real 2m44.089s
user 2m41.911s
sys 0m2.388s
- v3_read_csv.py
import numpy as np
import csv
fin = "data.csv"
with open(fin, newline="") as csvfile:
data = np.asarray([float(x) for x in (list(csv.reader(csvfile, delimiter=","))[0])])
print(data)
$ time python3 v3_read_csv.py
[0.00228202 0.00304794 0.00644779 ... 0.00259626 0.00812531 0.00063801]
real 0m1.583s
user 0m1.393s
sys 0m0.525s
Plot
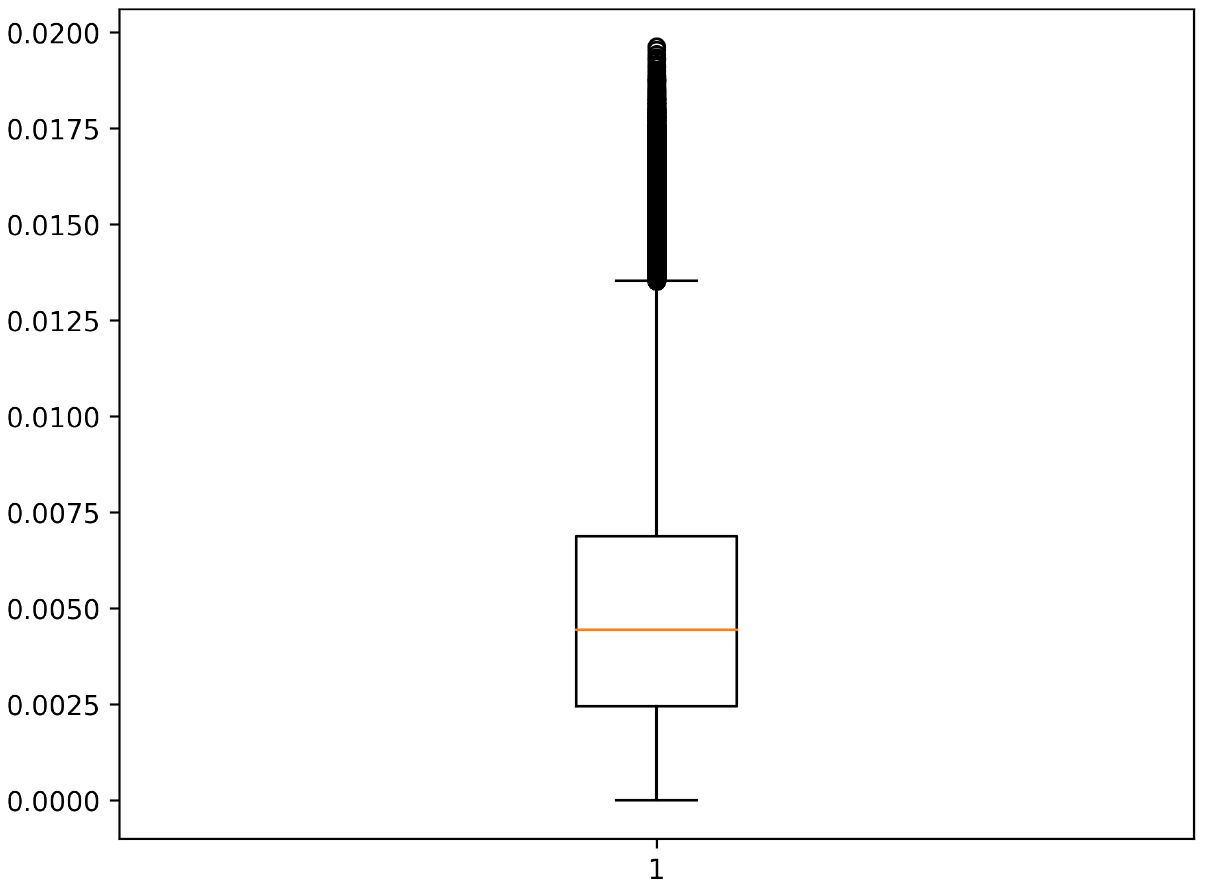
接下來是畫圖的部份。把所有點畫到畫布中會發現產生的 pdf 檔案蠻大,而且開啟時間蠻久。
- v4_plot.py
import numpy as np
import csv
import matplotlib.pyplot as plt
fin = "data.csv"
with open(fin, newline="") as csvfile:
data = np.asarray([float(x) for x in (list(csv.reader(csvfile, delimiter=","))[0])])
print(data)
fout = fin+".pdf"
fig, ax = plt.subplots()
ax.boxplot(data)
ax.autoscale()
plt.tight_layout()
plt.savefig(fout, bbox_inches="tight", dpi=300)
$ time python3 v4_plot.py
[0.00228202 0.00304794 0.00644779 ... 0.00259626 0.00812531 0.00063801]
real 0m5.063s
user 0m4.875s
sys 0m2.854s
$ ls -lh data.csv.pdf
Permissions Size User Date Modified Name
.rw-r--r-- 206k ben 5 Mar 10:25 data.csv.pdf
最佳化版本
有很多資料點其實是重複的,我當下覺得應該有辦法可以忽略重複的點,但是又不能對資料做過濾,因為這樣分佈就錯誤了。一個比較好的方法其實是在 python 先計算好分佈 (最大,最小,中位數,第一分位數,第三分位數)。
不過 matplotlib 提供 box plot 可以根據資料繪製盒狀圖,代表應該可以不用自行計算。因此朝向如何讓重複的點可以不被重複繪製。
後來查到 rasterized 選項3,可以將向量圖形轉成點陣圖,很大程度縮小產生的檔案大小。至此完整版的整理如下。
- v5_plot.py
import numpy as np
import csv
import matplotlib.pyplot as plt
fin = "data.csv"
with open(fin, newline="") as csvfile:
data = np.asarray([
float(x) for x in
(list(csv.reader(csvfile, delimiter=","))[0])])
print(data)
fout = fin+".pdf"
fig, ax = plt.subplots()
ax.boxplot(data)
ax.set_rasterized(True)
ax.autoscale()
plt.tight_layout()
plt.savefig(fout, bbox_inches="tight", dpi=300)
$ time python3 v5_plot.py
[0.00228202 0.00304794 0.00644779 ... 0.00259626 0.00812531 0.00063801]
real 0m3.128s
user 0m3.212s
sys 0m2.050s
$ ls -lh data.csv.pdf
Permissions Size User Date Modified Name
.rw-r--r-- 37k ben 5 Mar 11:46 data.csv.pdf
繪製結果